Finding Deals on UberEats with Node.js and GitHub Actions
How I was able to snag up UberEats buy-one-get-one-free (BOGO) deals from UberEats in my area. TL;DR.
Background
I recently started my batch at Recurse Center. Although I have been learning a lot and having a good time with all the people here, the food in this area is awfully expensive, and on some days I don't have time to prepare lunch at home. I looked at a couple of food delivery sites like DoorDash, GrubHub, etc. As it turns out, UberEats routinely offers BOGO deals at a good number of restaurants. It was very annoying to sift through all the nearby restaurants for what offers they have, so I wanted a way to quickly view all of the items that had an offer going on.
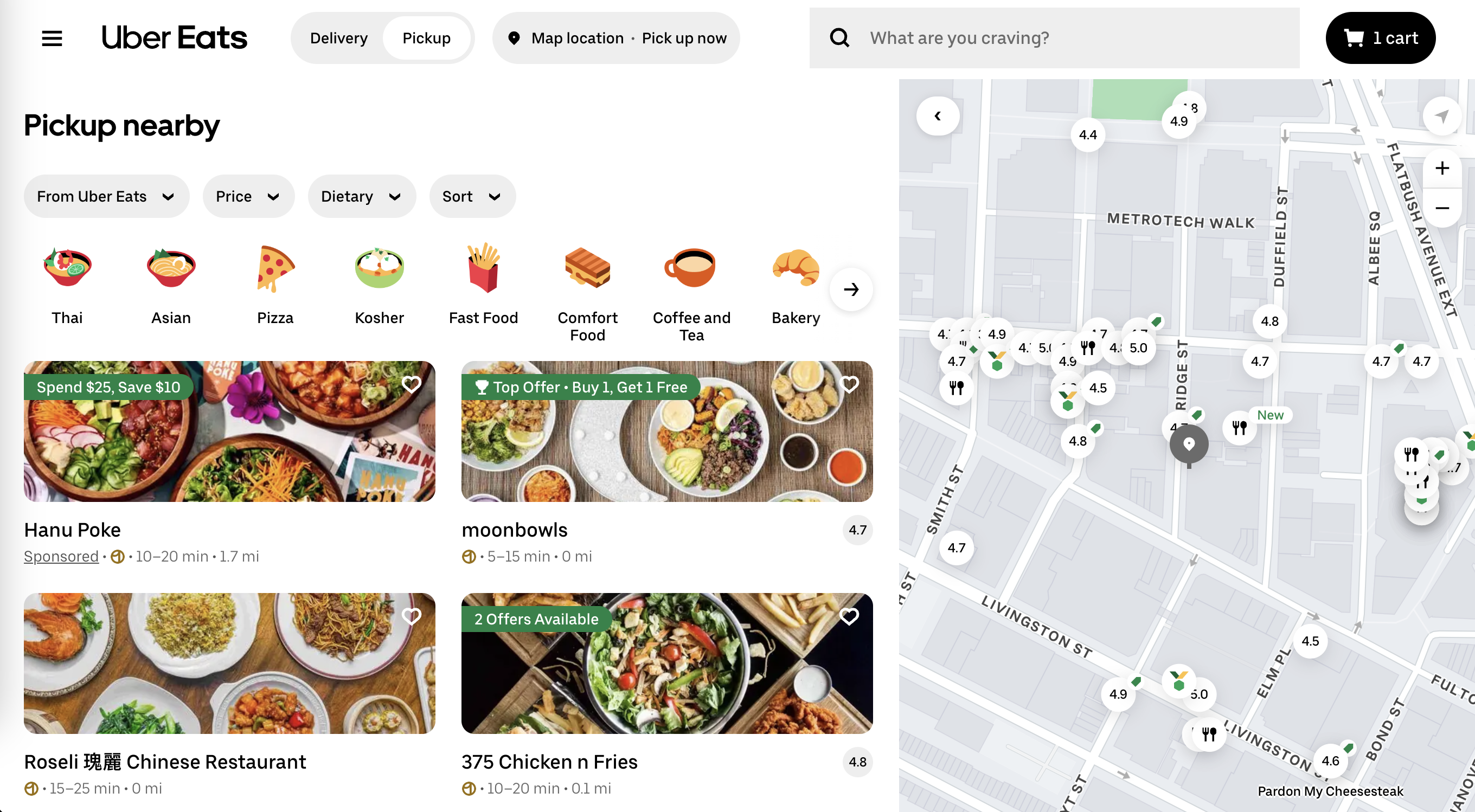
Investigation
As it turns out, UberEats doesn't really want you scraping their site. Most API endpoints have obscure names, the URL is encoded in some strange way, and the React state is quite annoyingly obfuscated. It's okay, though. As with any sort of reverse engineering, anything is possible (unless you encounter CAPTCHA, then you go on a long walk and consider whether all this is even worth it). Let's start with something simple.
The URL
First off, we need to find restaurants in our area, so let's navigate to UberEats and search for the current address (for Recurse Center, that's 397 Bridge St). On this page, we can see restaurants in our area. Let's try and pick apart the URL.
https://www.ubereats.com/feed
?diningMode=PICKUP
&pl=JTdCJTIyYWRkcmVzcyUyMiUzQSUyMjM5NyUyMEJyaWRnZSUyMFN0JTIyJTJDJTIycmVmZXJlbmNlJTIyJTNBJTIyaGVyZSUzQWFmJTNBc3RyZWV0c2VjdGlvbiUzQWRrcFQwMXY0d3p1N1VEWHp3MFBvTUElM0FDZ2NJQkNEUHQtVWpFQUVhQXpNNU53JTIyJTJDJTIycmVmZXJlbmNlVHlwZSUyMiUzQSUyMmhlcmVfcGxhY2VzJTIyJTJDJTIybGF0aXR1ZGUlMjIlM0E0MC42OTEzNiUyQyUyMmxvbmdpdHVkZSUyMiUzQS03My45ODUyJTdE
Of course, diningMode is either PICKUP or DELIVERY. Since my goal here is to save money, not spend it, we are going to be using PICKUP and not DELIVERY. As for the second parameter, pl, it definitely seems a bit trickier. Based on my years of professional hacking, I am going to take a guess and say that this is just Base64 encoded. You can try plugging this into an online Base64 decoder or do what I do and just use atob from the Chrome console.
> atob('JTdCJTIyYWRkcmVzcyUyMiUzQSUyMjM5NyUyMEJyaWRnZSUyMFN0JTIyJTJDJTIycmVmZXJlbmNlJTIyJTNBJTIyaGVyZSUzQWFmJTNBc3RyZWV0c2VjdGlvbiUzQWRrcFQwMXY0d3p1N1VEWHp3MFBvTUElM0FDZ2NJQkNEUHQtVWpFQUVhQXpNNU53JTIyJTJDJTIycmVmZXJlbmNlVHlwZSUyMiUzQSUyMmhlcmVfcGxhY2VzJTIyJTJDJTIybGF0aXR1ZGUlMjIlM0E0MC42OTEzNiUyQyUyMmxvbmdpdHVkZSUyMiUzQS03My45ODUyJTdE')
< '%7B%22address%22%3A%22397%20Bridge%20St%22%2C%22reference%22%3A%22here%3Aaf%3Astreetsection%3AdkpT01v4wzu7UDXzw0PoMA%3ACgcIBCDPt-UjEAEaAzM5Nw%22%2C%22referenceType%22%3A%22here_places%22%2C%22latitude%22%3A40.69136%2C%22longitude%22%3A-73.9852%7D'
Well, the resulting string just looks like it's been URI encoded so let's see what happens if we call decodeURIComponent on it.
> decodeURIComponent('%7B%22address%22%3A%22397%20Bridge%20St%22%2C%22reference%22%3A%22here%3Aaf%3Astreetsection%3AdkpT01v4wzu7UDXzw0PoMA%3ACgcIBCDPt-UjEAEaAzM5Nw%22%2C%22referenceType%22%3A%22here_places%22%2C%22latitude%22%3A40.69136%2C%22longitude%22%3A-73.9852%7D')
< {"address":"397 Bridge St","reference":"here:af:streetsection:dkpT01v4wzu7UDXzw0PoMA:CgcIBCDPt-UjEAEaAzM5Nw","referenceType":"here_places","latitude":40.69136,"longitude":-73.9852}
How nice, it looks like some clean and readable JSON. Let's just restructure it so we can inspect it a bit.
{
"address": "397 Bridge St",
"reference": "here:af:streetsection:dkpT01v4wzu7UDXzw0PoMA:CgcIBCDPt-UjEAEaAzM5Nw",
"referenceType": "here_places",
"latitude": 40.69136,
"longitude": -73.9852
}
So now, we have our decoding function,
const decode = pl => JSON.parse(decodeURIComponent(atob(pl)));
and inversely, our encoding function,
const encode = obj => btoa(encodeURIComponent(JSON.stringify(obj)));
After some testing of swapping out the latitiude, longitude, etc., it turns out that /feed bases its queries on the reference parameter. This means we can omit all the other fields and pass an encoded object that only has a reference field. For example:
> encode({ reference: 'here:af:streetsection:dkpT01v4wzu7UDXzw0PoMA:CgcIBCDPt-UjEAEaAzM5Nw' })
< 'JTdCJTIycmVmZXJlbmNlJTIyJTNBJTIyaGVyZSUzQWFmJTNBc3RyZWV0c2VjdGlvbiUzQWRrcFQwMXY0d3p1N1VEWHp3MFBvTUElM0FDZ2NJQkNEUHQtVWpFQUVhQXpNNU53JTIyJTdE'
When plugging this string into our pl parameter, the results are identical. We now have a programmatic way of generating URLs for a given location. The only problem is that I don't actually know what here:af:streetsection:dkpT01v4wzu7UDXzw0PoMA:CgcIBCDPt-UjEAEaAzM5Nw actually means. It's not a string I've ever seen before. Taking here:af:streetsection: to Google, I am led to the HERE developer docs. It seems to be some kind of string representing our address. I'm sure there's some way that by interacting with the HERE API, we can generate these strings for any given input. However, since I just want to use this scraper for only one location, I'll stick with the original URL that we had in our browser. Surprise! We did all this work just not to use any of it. It happens sometimes.
The Page
Let's see if we can do this the cool way without puppeteer. I start by viewing the source of the page and searching for "moonbowls". The reason I'm doing this is to check if the server prerenders the results and we can access them by just fetching the page's HTML.
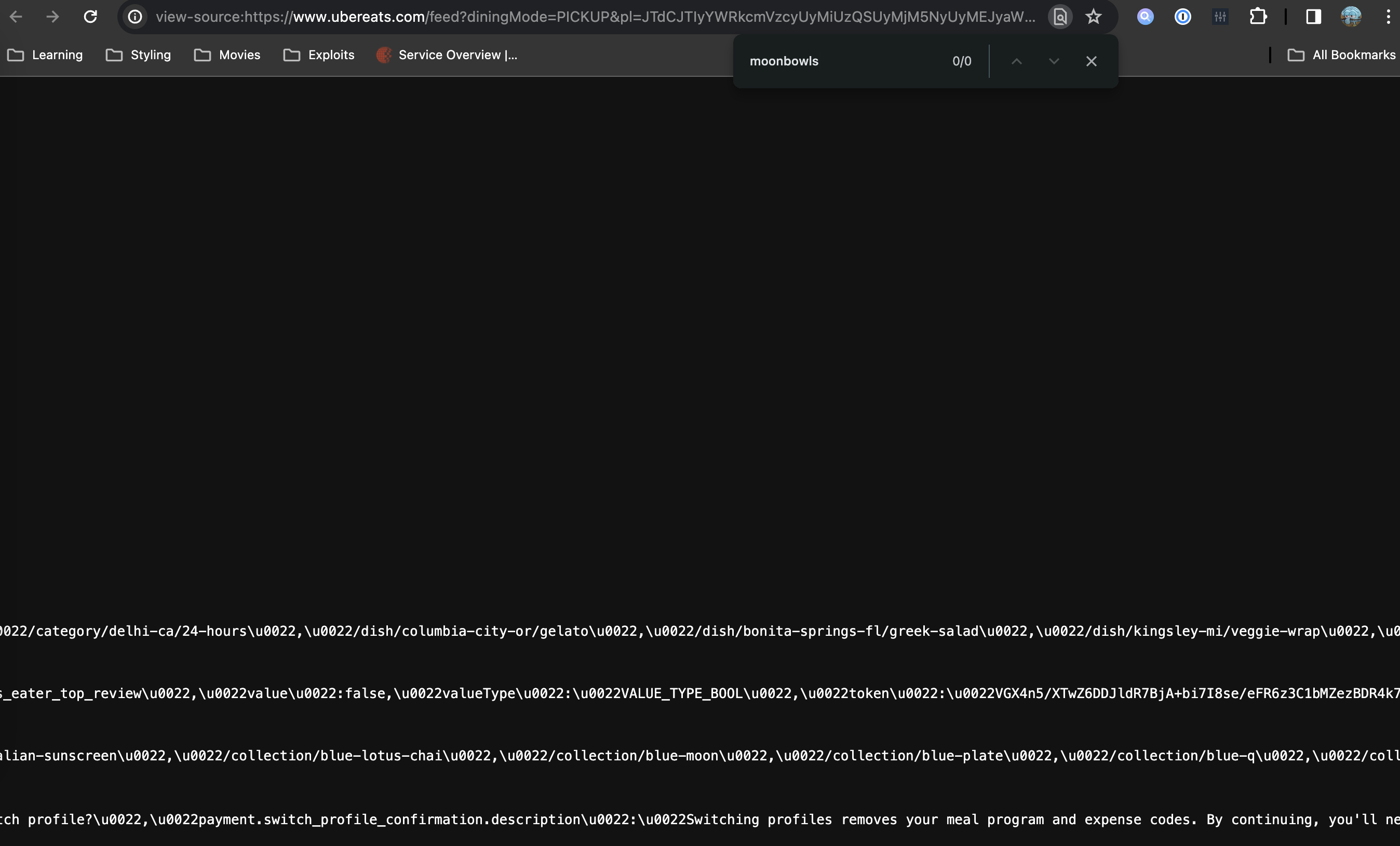
No results. Darn. To the Chrome DevTools network tab we go. In the network tab, we may click on the search button and enter "moonbowls". This will search for everything in all requests (the URL, the header, the body, etc.).
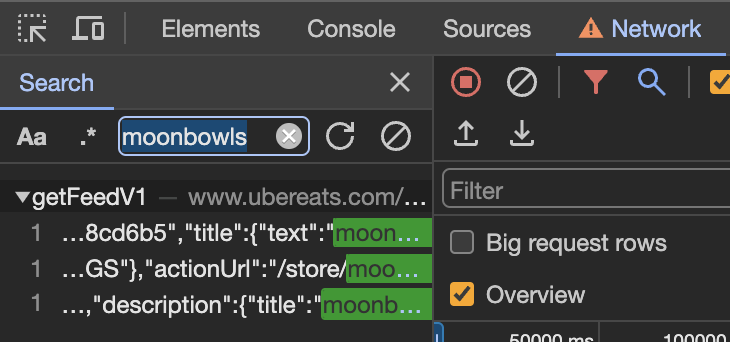
One hit! The page seems to be sending a POST request to https://www.ubereats.com/_p/api/getFeedV1?localeCode=en-US. Let's check out the payload it's sending.
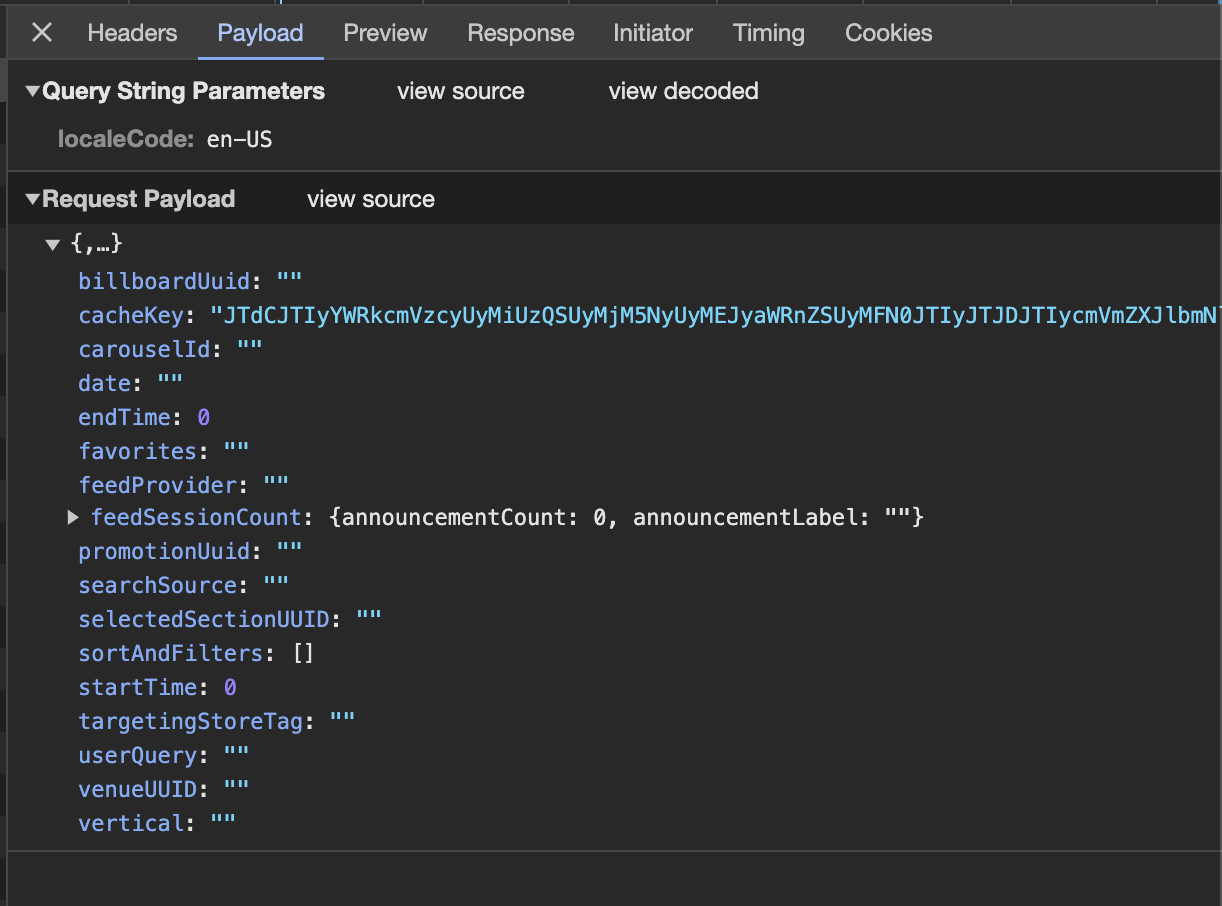
That's a lot of JSON fields, but most of them are empty. All but one. cacheKey seems to have another Base64 encoded string. (Partially omitted for clarity.)
"cacheKey": "JTdCJTIyYWR...45ODUyJTdE/PICKUP///0/0//JTVCJTVE/undefined//////HOME///////"
The keen among you may have realized that the Base64 string is the same as the one in our URL. This means that the cacheKey parameter is just our pl parameter concatenated with /PICKUP///0/0//JTVCJTVE/undefined//////HOME///////. After a quick test with another address, JTVCJTVE remains the same. Some of the other values in between the forward slashes are filled out and some aren't. It doesn't seem to matter for our purposes, so let's just keep /PICKUP///0/0//JTVCJTVE/undefined//////HOME/////// as a constant.
The API Request
Well, we have enough information to start making queries using an HTTP library. Here, I'll be using node-fetch since it's my personal favorite and Chrome DevTools lets you copy the request as a Node.js fetch call.
fetch("https://www.ubereats.com/_p/api/getFeedV1?localeCode=en-US", {
// copied straight from chrome
}).then(res => res.json()).then(console.log);
Running this results in the following.
{ status: 'failure', data: { message: 'bd.error.too_many_requests' } }
Well, that sucks. It seems like UberEats might be doing some cookie stuff to make clients use a new cookie for each request. We can try and get around this by
- Maintaining the cookies using a cookie jar, which will update our cookie state based on set-cookie response headers.
- Tracking the requests and responses that the browser makes, and trying to mimic them so we can have a browser-like cookie state.
I did try this route for a good while before coming to the conclusion that it was very difficult and the server always seemed to figure out I was not a real browser. Well, when the server wants you to be a browser, why not just be a browser?
Puppeteer
Puppeteer, the greatest invention since sliced bread, is an API for controlling a headless Chrome instance. This means we can have a browser physically visit the UberEats site, load the page, and then scrape the information ourselves from the elements on the page. I typically try to avoid using puppeteer since it sort of feels like cheating and uses a lot more resources compared to a few HTTP requests. First, install puppeteer with npm i puppeteer. After that, get it to visit our target URL. Note: headless: false makes it so that we can see the browser in action. In production, one should set this to true (actually 'new' to avoid deprecation warnings).
const feedURL = 'https://www.ubereats.com/feed?diningMode=PICKUP&pl=...';
console.log('launching puppeteer...');
const browser = await puppeteer.launch({ headless: false });
const page = (await browser.pages())[0];
console.log('getting nearby restaurants..');
await page.goto(feedURL);
Now that we've visited the page, let's open the Chrome element inspector and find a path to our restaurant cards.
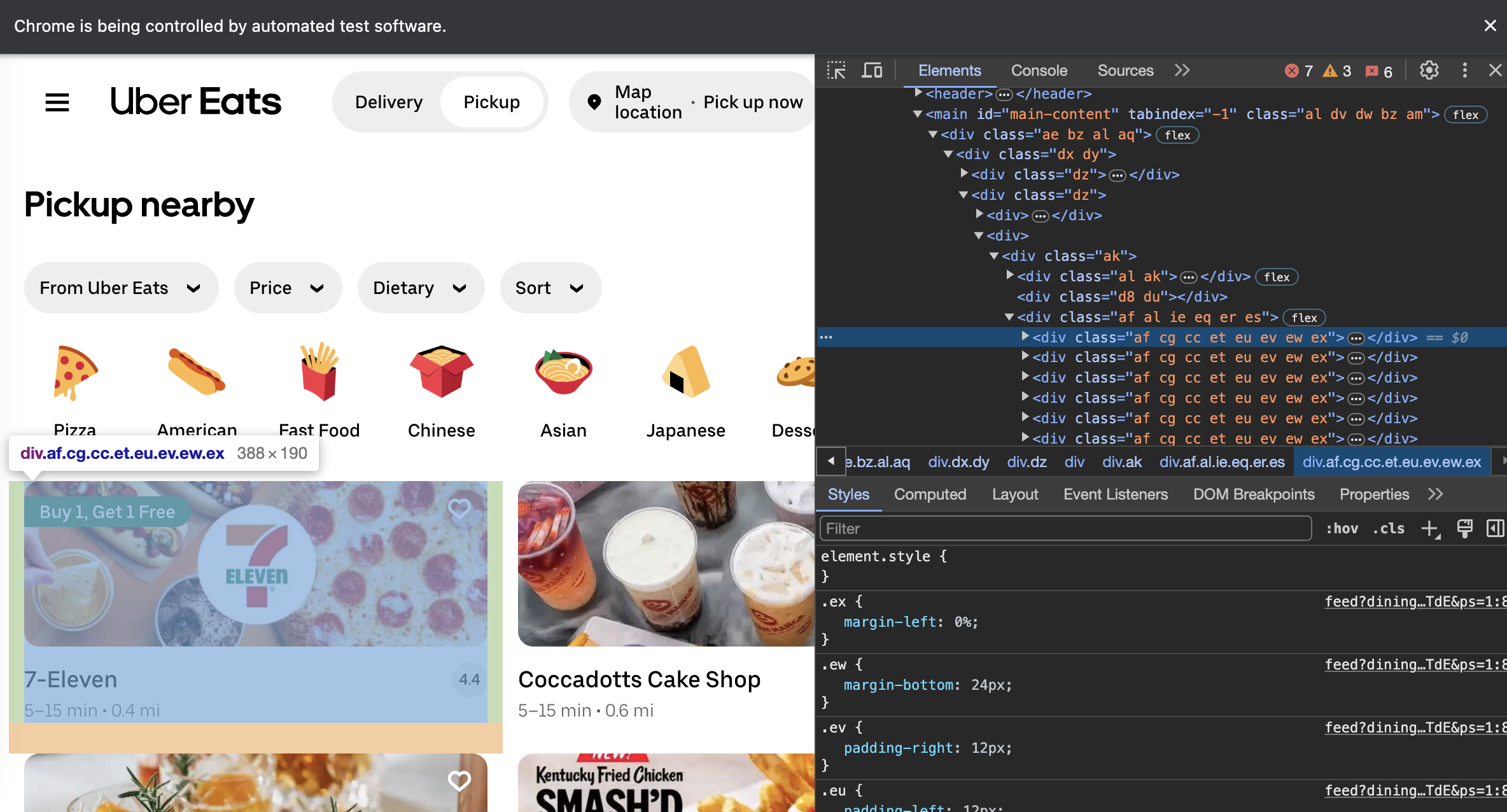
As it turns out, these class names are minified, which means that if UberEats were to ever deploy a new version, it would likely break our scraper since the minified filenames are highly susceptible to change. Instead, let's use a selector which is more concrete and not based on classes. Note: the way I'm using a query selector here is by pressing CMD/CTRL+F in the Chrome Element Inspector.
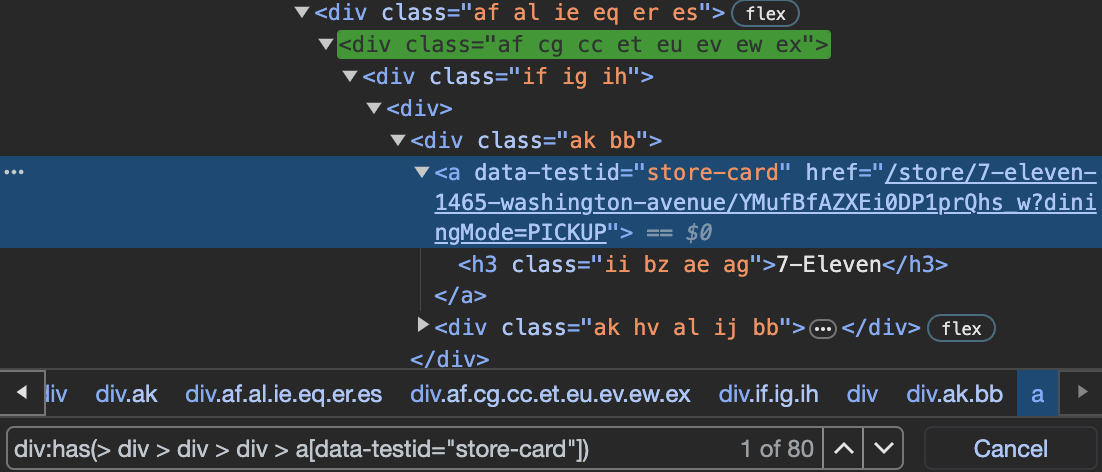
One of the anchor tags inside the card has an attribute called data-testid which is always "store-card". This seems pretty good and when querying the page for a[data-testid="store-card"], we get 80 results, which is the number we want. The selector I went with is div:has(> div > div > div > a[data-testid="store-card"]). Since we want to select the parent div of the anchor element, we may use the :has() selector to help us. Now that we have the card, we want to check if it has a green ribbon, which means that it is likely to have a BOGO deal. If it does have a green ribbon and that green ribbon contains the text Buy 1, Get 1 Free or n Offers Available, we want to store the URL of the restaurant page to be scraped later. The code we end up with looks like this. Note: we are using page.waitForSelector(cards) here to wait until the cards are present on the page before scraping them.
const cards = 'div:has(> div > div > div > a[data-testid="store-card"])';
await page.waitForSelector(cards);
const restaurants = [];
for (const el of await page.$$(cards)) {
const offer = await el.evaluate(e => e.querySelector('picture + div > div')?.textContent) || '';
if (offer.includes('Get 1 Free') || offer.includes('Offers')) {
restaurants.push(await el.evaluate(e => e.querySelector('a').href));
}
}
console.log(`${restaurants.length} potential restaurants with offers found! closing puppeteer...`);
await browser.close();
Back to Fetch
Anyway, that's all we need from puppeteer. As it turns out, there is a straightforward way to parse the restaurant menu data from the page without making any special API requests. If we go to the URL of the restaurant (ex: moonbowls). When we view source and search for a particular item on their menu (ex: BBQ Chicken Bowl), we can find that the data is contained within the server-sent HTML. It's all in this one script tag that looks like this:
<script type="application/json" id="__REACT_QUERY_STATE__">
{\u0022mutations\u0022:[],\u0022queries\u0022:[{ and on and on and on...
</script>
Let's go ahead and get this tag from a script using the following code. Note: it turns out that we need a "good" User-Agent
const body = await fetch(url, {
headers: {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
},
}).then(res => res.text());
const reactData = body.match(/__REACT_QUERY_STATE__">(.*?)<\/script>/s)[1];
const rawData = JSON.parse(decodeURIComponent(JSON.parse(`"${reactData.trim()}"`)));
Here, I'm just fetching the page and parsing the context as text. Then, I run a regular expression on the text to find whatever is inside of the script tag. The data is a bit weird, but I first tried to unescape the string by wrapping it with quotes and using JSON.parse. After that, I realized it was still URI encoded so I use decodeURIComponent. Finally, we can JSON.parse that.
Cleaning and Saving the Data
Everything from this point is mostly smooth sailing. Just apply this logic to every restaurant URL we have, get the fields from the JSON that are relevant to us, and save them all to a file. Note: there is a ton of JSON fields and sifting through this is not fun. The code we end up with looks like this.
const allCompiled = [];
for (let i = 0; i < restaurants.length; i++) {
const url = restaurants[i];
console.log(`(${i+1}/${restaurants.length}) fetching ${url}...`);
const body = await fetch(url, {
headers: {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
},
}).then(res => res.text());
const reactData = body.match(/__REACT_QUERY_STATE__">(.*?)<\/script>/s)[1];
const rawData = JSON.parse(decodeURIComponent(JSON.parse(`"${reactData.trim()}"`)));
const { data } = rawData.queries[0].state;
const [section] = data.sections;
if (section.isOnSale && data.catalogSectionsMap[section.uuid]) {
const items = new Map();
for (const { payload } of data.catalogSectionsMap[section.uuid]) {
for (const item of payload.standardItemsPayload.catalogItems) {
items.set(item.uuid, item);
}
}
const deals = [];
for (const item of items.values()) {
if (item.itemPromotion) deals.push(item);
}
// deals found
if (deals.length) {
// formatting the json to our liking
const compiled = JSON.parse(data.metaJson);
compiled.deals = deals;
delete compiled.hasMenu;
allCompiled.push(compiled);
console.log(`got data for ${compiled.name}: ${deals.length} deal(s) found`);
}
}
await new Promise(r => setTimeout(r, 3000)); // sleep for 3 secs to avoid ratelimiting
}
fs.writeFileSync('./scraped.json', JSON.stringify(allCompiled)); // output our deals to scraped.json
GitHub Action
And that's it! I did mention that we are using a GitHub Action to automatically scrape the data so here is the script for that. Every 10 minutes, it checks out the repository, runs our JS file, and commits the changed files back to the repository. Note: GH_TOKEN is a repository secret that contains a GitHub personal access token with write content permission to the repository.
name: Cron Scrape
on:
schedule:
- cron: "*/10 * * * *"
permissions:
contents: write
jobs:
build:
runs-on: ubuntu-latest
name: Run scrape.mjs and commit changes
env:
GITHUB_TOKEN: ${{ secrets.GH_TOKEN }}
steps:
- uses: actions/checkout@v3
- name: Setup Node
uses: actions/setup-node@v3
with:
node-version: 20.3.0
- run: npm i
- run: |
git config --global user.name "gh-actions"
git config --global user.email "[email protected]"
git remote set-url origin https://git:${GITHUB_TOKEN}@github.com/${{github.repository}}.git
- run: npm run main
- run: git commit --allow-empty -am "update scraped.json"
- run: git push
Rendering the Data
With the data successfully scraped, we may now make a nice user interface. I did so using GitHub Pages and you can visit it here. The source code for the page itself is here.
Final Notes
I hope you can go and start using puppeteer yourself. I barely scratched the surface of puppeteer's capabilities, but these are probably the most useful parts. During this small project, I learned that it's better to quit early and opt for the "easier" method sooner as sometimes all you need is a working product that can feed some hungry stomachs. Hope you've enjoyed. See you again!